Burn After Reading:
Online Adaptation for Cross-domain Streaming Data
(ECCV 2022)
Luyu Yang Mingfei Gao Zeyuan Chen Ran Xu Abhinav Shrivastava Chetan Ramaiah
Salesforce Research University of Maryland
Pdf | Code
Abstract
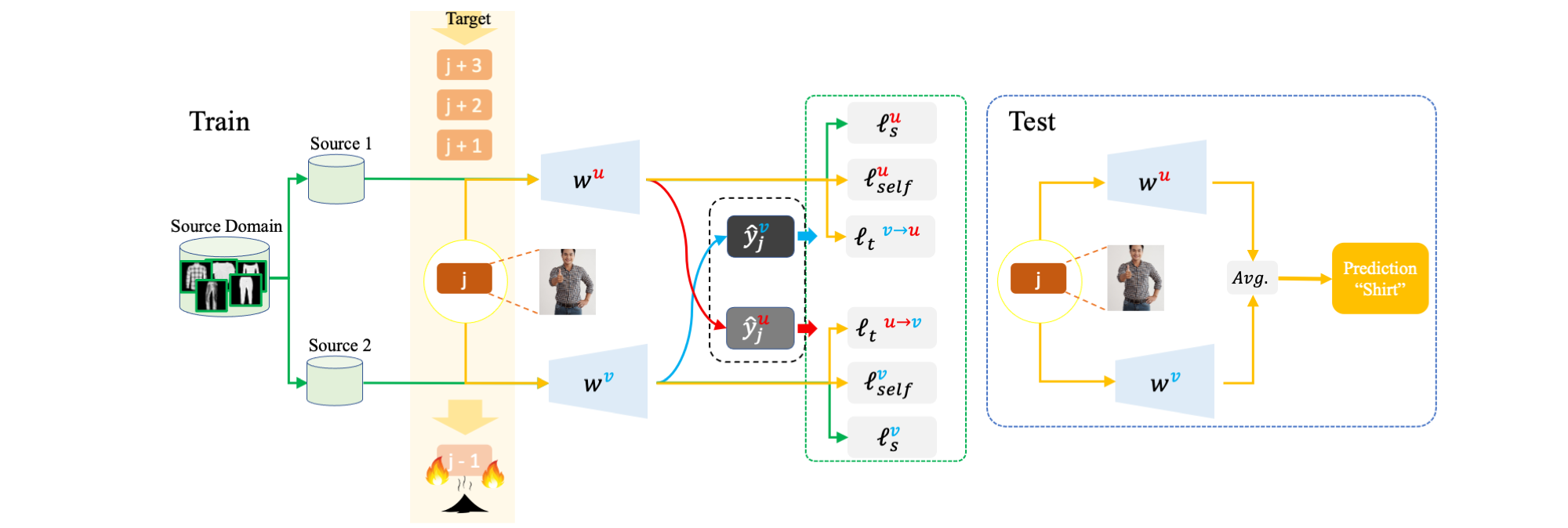
In the context of online privacy, many methods propose complex security preserving measures to protect sensitive data. In this paper we note that: not storing any sensitive data is the best form of security. We propose an new task called "Burn After Reading", i.e. each online sample is permanently deleted after it is processed. Our framework utilizes the labels from the public data and predicts on the unlabeled sensitive private data. To tackle the inevitable distribution shift from the public data to the private data, we propose a novel unsupervised domain adaptation algorithm that aims at the fundamental challenge of this online setting--the lack of diverse source-target data pairs. We design a Cross-Domain Bootstrapping approach, named CroDoBo, to increase the combined data diversity across domains. To fully exploit the valuable discrepancies among the diverse combinations, we employ the training strategy of multiple learners with co-supervision. CroDoBo achieves state-of-the-art online performance on four domain adaptation benchmarks.
Task Definition
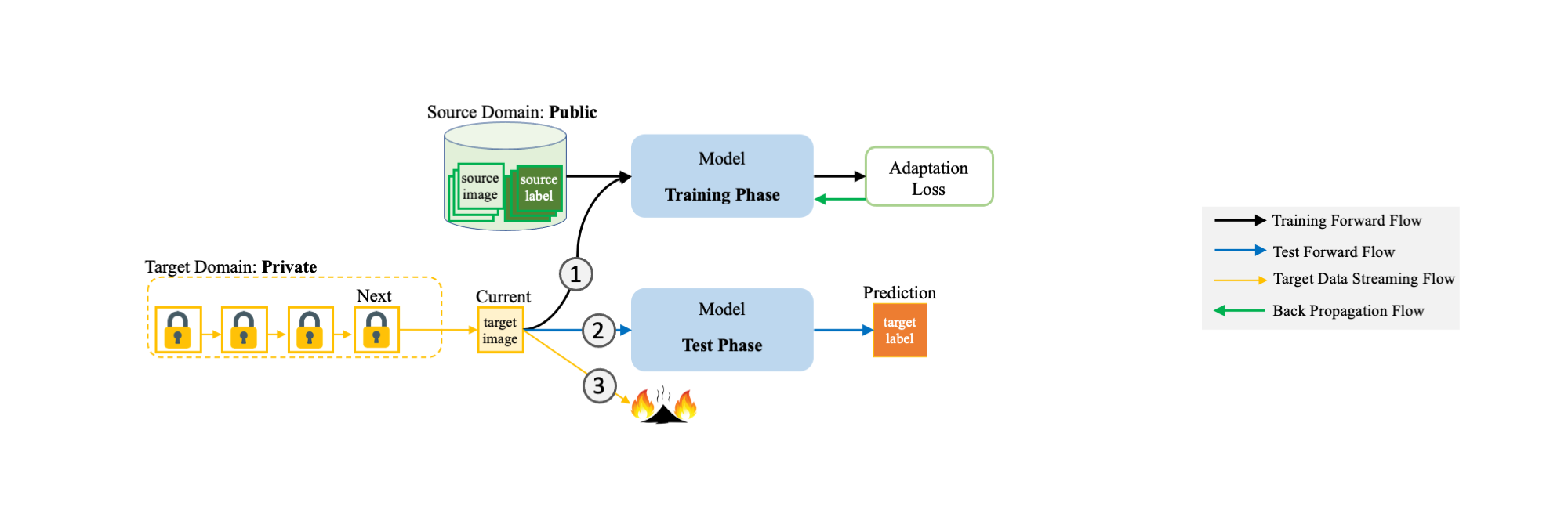
We propose a new task for online data privacy, called "Burn After Reading", it takes two inputs: a public dataset with ground-truth (source), and a private dataset without any label information (target). There is a distribution shift between the two datasets. Meanwhile, we assume no time constraint on the public dataset (i.e., public dataset is accessible at anytime), but each private sample/batch is deleted before the next one arrives (order of arrival is random). Our goal is to success on the private target data.
The following shows the data-flow "Burn-After-Reading" at one iteration. The iteration contains a training and a test phase. In training phase, the model takes a {data, label} pair from the public dataset, and an unlabeled {data} from the private dataset. The model updates based on an adaptation loss and then moves to test phase on the private {data}. After tested, the current target data is permanently deleted and shall not be reused.
Generally speaking, each private data/batch is (1.) trained (2.) tested (3.) deleted.
Paper
Citation
Luyu Yang, Mingfei Gao, Zeyuan Chen, Ran Xu, Abhinav Shrivastava, Chetan Ramaiah. "Burn After Reading: Online Adaptation for Cross-domain Streaming Data", ECCV 2022.
